

アテンションで注目!AIの「言葉」である自然言語処理の仕組み
盛 堃
リープリーパー


今回は、最近話題のAI技術「RAG」について解説します。ChatGPTやGPT-4/GPT-4oなどの大規模言語モデル(LLM)がブームになっている中で、RAGという言葉をよく耳にするようになりました。でも、正直なところ、私自身はこれまでRAGについてあまり知識がありませんでした。実際に論文でも提唱されているので、改めてしっかり調べてみることにしました。
私は普段、BlueMemeというIT企業で研究員をしている、バイオインフォマティクス (生物が持つさまざまな情報をITシステムで解析する分野)を専門とする大学院生です。LLMの技術は日々進化していて、私の研究分野にも大きな影響を与えそうです。そこで、RAGについて理解を深めるべく、調査してみました。さらに、生命科学におけるRAGの応用についても考えてみます。
まず、RAGの正体から探ってみましょう。RAGは「Retrieval-Augmented Generation」の略で、日本語では「検索拡張生成」と訳されることがあります。これは、大規模言語モデル(LLM)の能力を外部知識で補強する技術のことを指します。簡単に言えば、RAGは「LLMに外部の情報源をプラスして、より正確で最新の情報を提供できるようにする方法」といったところでしょうか。
ここで疑問が浮かびます。ChatGPTのような強力なAIがあるのに、なぜRAGが必要なのでしょうか?
実は、LLMには以下のような課題があります。
RAGは、これらの課題に対するソリューションとして注目を集めているのです。
実際に過去記事で、LLMはハルシネーションを起こすことについても紹介していたので、より頑健なシステムを作るための技術ということですね。
RAGの基本的な仕組みは、次のようなステップで構成されています。これにより、LLMは最新かつ正確な情報を基に回答を生成できるようになります。
RAGの歴史は、生成AIの歴史と共にあるようです。2020年にFacebook (現Meta)が出したRAGの提唱論文で、数学的な観点を観察しましょう。その論文とは、Patrick Lewis氏らによって発表された2020年の、”Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” です。
そのアルゴリズムの可視化は、下のような図になっています。RAGは文章から文章を生むようなシステムなので、具体的にその中身で何が起こっているかが書かれています。
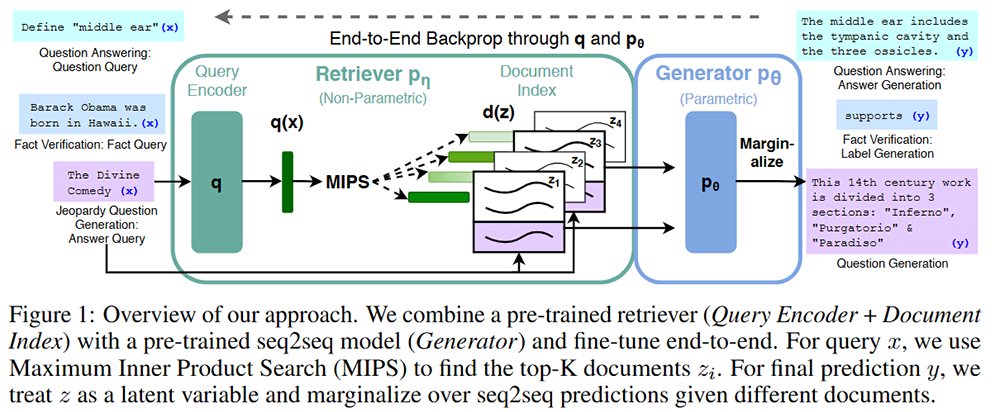
RAGのアルゴリズムは、主に以下の要素で構成されています。
RAGの処理フローは次のとおりです。
著者らによると、プロセスは更新可能なパラメーターを持っているので(微分可能なプロセスと表現されている)、エンドツーエンドでの学習が可能だと思われます。
RAGを導入することで、以下のような利点が得られます。
私の専門分野であるバイオインフォマティクスでも、RAGは大きな可能性を秘めています。RAGを活用することで、以下のような、より正確で最新の知見に基づいた情報処理が可能になりそうです。
すでにDNA言語モデルの研究も出つつあるので、RAGとの統合は、今後のバイオインフォマティクスにおけるトレンドの一つになるかもしれないと感じました。
RAGについて調べてみて、この技術がLLMの限界を克服し、より信頼性の高いAIシステムを実現する可能性を持っていることがわかりました。RAGは比較的新しい技術なので、やはり生成AIの登場はIT技術に大きな変革を起こしていることが分かりますね。
1.Lewis, Patrick, et al. [2005.11401] “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” *Advances in Neural Information Processing Systems* 33 (2020):9459-9474.
https://arxiv.org/abs/2005.11401
2. RAGの概要まとめ、今後 #rag – Qiita
https://qiita.com/applego/items/29546ed50d65bc9a8d56#rag%E3%81%AE%E6%AD%B4%E5%8F%B2





