
AppleやTikTokなど続々!パスワードに代わって普及するパスキーとは
リプリパ編集部
リープリーパー


今回は、今話題の対話型AIサービスChatGPTを提供しているOpenAI社の研究者たちが、どのようなアイデアでChatGPTを開発したのかについて解説します。ChatGPTの学習メカニズムについて知ると、また新しい興味が湧くかもしれません。
ChatGPTは、OpenAIによって開発された人工知能言語モデルで、インターネット上のテキストデータを学習することで、質問に答えたり、文章を生成したり、さまざまなタスクを実行する能力があります。GPT-3からGPT-3.5、そしてGPT-4と、GPTシリーズの進化の過程で性能が向上し、応用範囲が広がっています。
この記事では、同社が出している以下のプレプリントを、ChatGPTを活用しながらまとめてみました。タイトルは、”Training language models to follow instructions with human feedback”(言語モデルが指示に従うように、人間のフィードバックで訓練する)です。ChatGPTの技術の肝は、このタイトルにある通り「人間のフィードバックを用いる」という点です。ChatGPTは、自然言語処理の技術を用いて、人間と同じように自然な文章を生成し、コミュニケートできますが、その訓練課程で、「人間のフィードバック」を用いているということです。
ChatGPTで用いられている学習アルゴリズムは、Reinforcement Learning from Human Feedback(RLHF)です。これは、直訳すると「人間のフィードバックによる強化学習」です。つまり人間の役割は、モデルが生成した回答に対して評価を下すことです。
人間の評価者からフィードバックを受け取ると、モデルはそのフィードバックを元に学習していきます。人間からもらったフィードバックを手掛かりに、『より人間にとって好ましい回答は何か』をモデルが学習していくのです。これがRLHFの考え方で、これにより、モデルはより人間にとって適切な回答や文章を生成する能力を身につけていきます。
では、なぜOpenAI社の研究者たちは、AIだけで完結させずに人間のフィードバックで学習させることを選んだのでしょう?
その背景には、ChatGPT以前の言語モデル(LM)は、事実をでっち上げたり、偏ったり毒性のあるテキストを生成したり、単純にユーザーの指示に従わないといった、意図しない振る舞いを示すことが多かったことがあります。技術的な改良を加えることで、ユーザーの指示に役立ってアプリを安全に動作させる必要があったことを意味します。
研究者たちは、人間のフィードバックを明示的に取り入れてモデルを学習することで、人間の好みに寄り添った、正確で有益な回答を生成できる、つまりより「人間ライク」な人工知能を作れるはずだ!!と考えたということになります。
実際、このRLHFアルゴリズムの導入により、問題に対するモデルの理解が深まり、人間にとって有益で魅力的な回答を提供できるようになったことが報告されています。人間の評価者が、適切な回答は高く評価する一方で、適切でない回答には低い評価を与えることで、モデルは適切な回答を生成する方向に学習を進めることができます。
論文中で紹介されているRLHFのワークフローを見てみましょう。具体的には、次の図のような流れです。
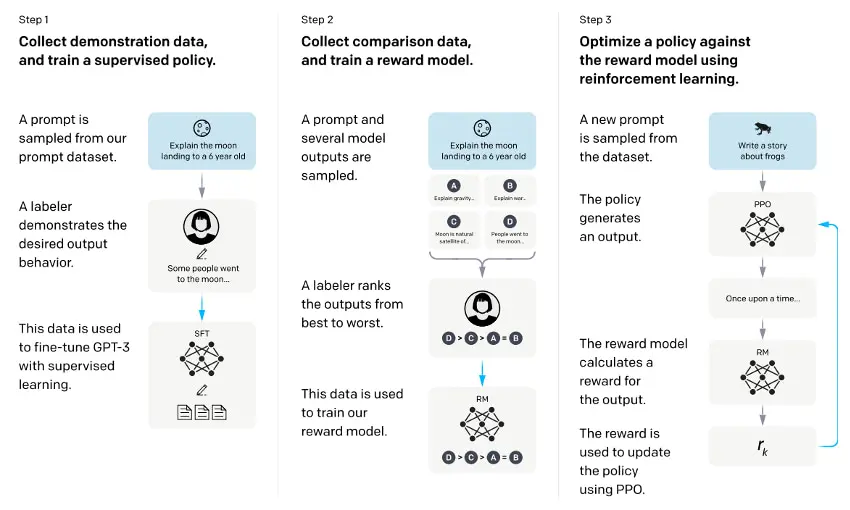
プロンプト(指示命令)文に対する好ましい回答文を人が書きます。これを教師データとして、既存のGPT-3言語モデルを教師あり学習します。
ステップ2が、前述の人間によるフィードバックです。評価者は、モデルが提示した回答に対して評価を下し、フィードバックします。次の図が示している通り、モデルが提示した複数の回答を人が好ましい順にランキングで評価します。これにより、人間の代わりに文の良し悪しを評価してくれる報酬モデルを訓練します。
ステップ1で微調整したモデルが、フィードバックによる改善対象モデルとなります。強化学習の枠組みを使って、ステップ2で訓練した報酬モデルの出力を最大化するように、ステップ1のモデルをさらに改善していきます。ややこしいですが、一連のプロセスを繰り返すことで、ChatGPTは評価者から得たフィードバックを学習し、より人間ライクな回答を生成する能力が向上していきます。
このように、モデルを人間の意図に合わせることはアラインメント(alignment)と呼ばれています。アラインメントのために採用されたRLHFアルゴリズムは、元々は、シミュレーション環境などにおける、単純なロボットのトレーニング用に提唱された理論のようです。
ここで紹介した論文ではInstructGPTという名前でモデルが紹介されていますが、これが現在ChatGPTに搭載されているGPT-3.5モデルのことです。正確には、OpenAIの公式サイトによると、GPT-3.5はデータ収集の設定に若干の違いを入れて、InstructGPTを訓練しているようです。ただ、GPT-3.5モデルのさらにその進化版のGPT-4は、これよりさらに性能が良くなっていますが、今のところGPT-4に関しては詳細な論文は出ていません。
言語モデルはとても興味深くて、ChatGPTのような対話チャットのみならず、私の専門とするバイオテクノロジー分野など、一見関係なさそうなところにも使われていてとても応用が広いので、次回はその話をしたいと思います。





