






GPT-4.5登場!人に寄り添った感情的な会話を研究者が試してみた
盛 堃
リープリーパー


Google DeepMindとQuantum AIチームが共同で開発した人工知能システム「AlphaQubit」が、量子コンピューターの実用化への大きな一歩を示しました。これは、量子誤り訂正に関する画期的なAI技術です。
昨年2024年11月にNature誌に掲載された研究では、従来手法と比較して最大30%のエラー削減を実現し、より信頼性の高い量子計算への道を開いたことが報告されています。今回の記事では、このAlphaQubitについて調べていきます。
量子コンピューターが実用化されるには、論理エラー率を1兆回の演算につき1回以下という極めて低い水準にまで抑える必要があります。しかし、現在のハードウェアでは1回の演算あたり0.1%から1%という高いエラー率が発生していて、実用レベルには遠く及びません。
このギャップを埋めるには、複数の物理量子ビット(キュービット)を組み合わせて1つの論理量子ビットを構成する、「量子誤り訂正」という技術が不可欠とされています。これは、情報を冗長に保存することで、個々のエラーを検出・訂正できるようにする手法です。
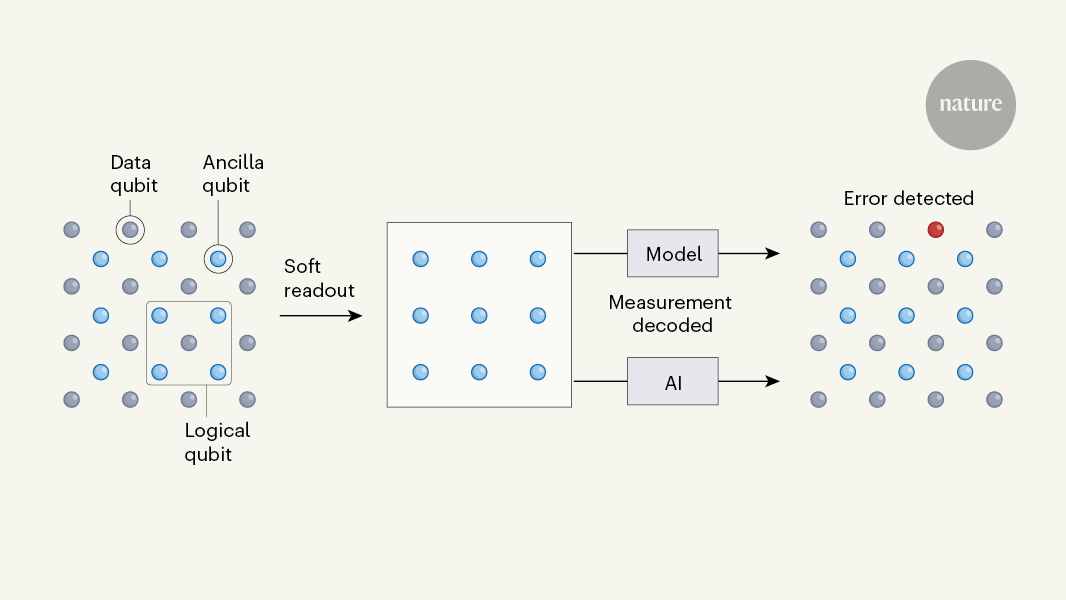
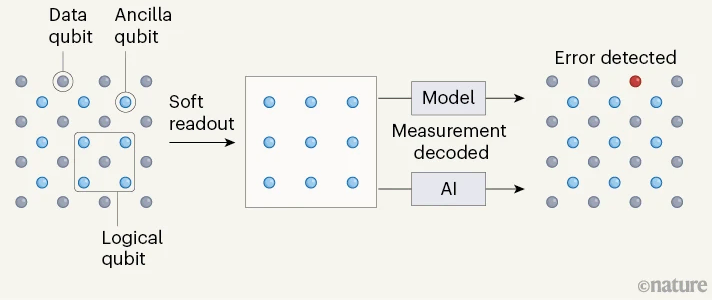
量子コンピューターでエラー訂正を実施するためには、以下の3種類の量子ビットが協調して働く必要があります。
1. データ量子ビット (Data qubit)
情報を実際に保持する量子ビットです。格子状に配置され、量子情報の処理を担います。しかし、これらは外部からの擾乱に対して非常に敏感です。温度変化や電磁干渉、さらには他の量子ビットとの望まない相互作用によっても、エラーを起こしてしまいます。
2. 補助量子ビット (Ancilla qubit)
データ量子ビットの状態を監視する「見張り役」として機能します。データ量子ビットを直接測定すると量子状態が壊れてしまうため、補助量子ビットを介して間接的にエラーを検出します。これらは格子の各交点に配置され、隣接するデータ量子ビットの状態を定期的にチェックします。
3. 論理量子ビット (Logical qubit)
これは物理的な実体というよりも、複数のデータ量子ビットと補助量子ビットから構成される「仮想的な」量子ビットです。1つの論理量子ビットは、数十から数百の物理量子ビット(データ量子ビットと補助量子ビット)から構成されます。この冗長性により、一部の量子ビットでエラーが発生しても、全体としての量子情報を保護できます。
イメージとしては、添付の図をみると分かりやすいと思います。
これらの量子ビットは、以下のように協調して動作します。
量子誤り訂正において最も重要な課題の一つが「デコーディング」です。これは、補助量子ビット(アンシラビット)から得られる測定結果を解釈し、実際にどのようなエラーが発生したかを特定し、適切な訂正操作を決定するプロセスを指します。
従来は、人間が設計したアルゴリズムでデコーディングを実行していました。代表的な手法である最小重みマッチング(MWPM)は、エラーが単発的に発生するケースには効果的でした。しかし、量子ビット数が増えノイズが複雑になると、物理的に近接する量子ビット間の望ましくない相互作用(クロストーク)や、計算に使用する状態以外への遷移(リーケージ)といった複雑なエラーに対応できないという課題がありました。
AlphaQubitは、この課題に対して以下の3つの革新的なアプローチで挑みました。
第一に、事前に決められたエラーモデルに依存せず、データから直接学習する方式を採用しました。2段階の学習プロセスを経ることで、理想的な環境での基本的なエラーパターンから、実際のハードウェアで発生する複雑なノイズまでを段階的に学習していきます。この適応的な学習により、従来の手法では見落としがちだったエラーパターンや相関関係も捉えることができます。
第二に、「ソフトリードアウト」という新しい測定手法を導入しました。量子状態の測定では、実際には測定値に不確実性が含まれています。従来のデコーダーは測定結果を強制的に0か1に二値化していましたが、AlphaQubitは測定値の確率分布情報を保持したまま処理します。これにより、量子状態についてより豊かな情報を活用でき、より正確なエラー訂正が可能になりました。
第三に、大規模言語モデルで成功を収めているTransformer型のニューラルネットワークを採用しました。この構造により、空間的に離れた量子ビット間の相関や、時系列に沿ったエラーの伝搬パターンなど、複雑な関係性を効率的に学習できます。注目機構(アテンション)を用いることで、エラーの検出と訂正に関連する重要な特徴を動的に抽出することが可能になりました。
この3つの革新により、AlphaQubitは従来の手法を大きく上回る性能を実現しました。特に重要なのは、この手法が量子ハードウェアの進化に合わせて自己改善できる点です。これは、将来的な大規模量子コンピューターの実現に向けて、極めて重要な特徴となります。
量子エラー訂正において、AIが担う中心的な役割は前述のデコーディングと呼ばれる作業です。これは、量子ビットの測定結果から、どのようなエラーが発生したかを推測し、適切な訂正操作を決定する過程です。
従来の古典的なアルゴリズムでは、あらかじめ設定された規則に従ってエラーを推測していました。しかし実際の量子システムでは、以下のような問題があります。
AlphaQubitは、これらの複雑な要因を総合的に判断し、最も確からしいエラーパターンを推定します。そして、その推定に基づいて適切な訂正操作を実行することで、エラーの蓄積を防ぎます。
特に革新的なのは、AlphaQubitが測定結果の確率的な情報(「ソフトリードアウト」と呼ばれる)も活用できる点です。従来のデコーダーは測定結果を0か1の二値でしか扱えませんでしたが、AlphaQubitは測定の確からしさも考慮に入れることで、より正確なエラー訂正を実現しています。
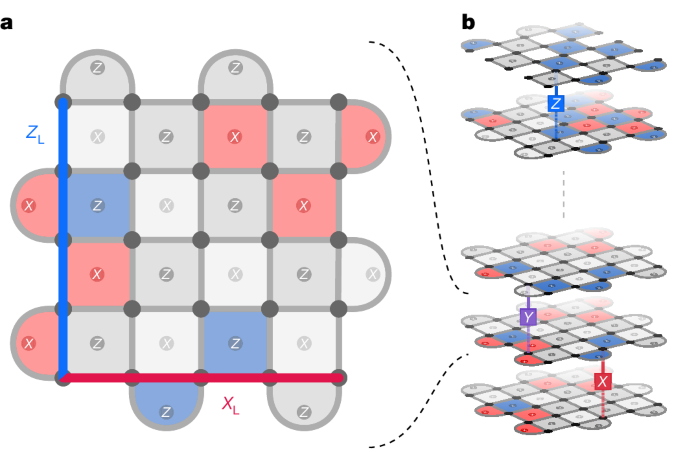
まず、表面コードについて説明する必要がありますね。表面コードは、量子誤り訂正の代表的な方式の一つです。2次元平面上に量子ビットを格子状に並べ、隣接するビット同士で定期的にチェックすることで、エラーを検出・訂正する仕組みです。
この格子の大きさを「距離」と呼び、例えば3×3の格子であれば「距離3」、5×5の格子であれば「距離5」となります。距離が大きいほど、より強力なエラー訂正が可能になりますが、必要な物理量子ビットの数も増えていきます。
GoogleのSycamoreプロセッサーを使用した実験では、AlphaQubitは以下のような成果を示しました。
まず距離3(3×3格子)の小規模なシステムでは、従来のデコーダーと比べてエラー率を6%削減することに成功しました。より大規模な距離5(5×5格子)のシステムでは、さらに効果が高まり、エラー率の30%削減を達成。さらに、シミュレーション実験では距離11(11×11格子、241個の物理量子ビットを使用)という大規模なシステムまでスケールできることを実証。加えて、10万回という多数の繰り返し演算でも、安定した性能を維持できることが確認されました。
AlphaQubitの最大の特徴は、大規模言語モデルで使用されているTransformer型のニューラルネットワークを、量子誤り訂正に応用した点です。システムは以下のような構造で設計されています。
デコーダーの状態表現
各安定化演算子(格子中の測定点)に対して、独自のベクトル表現を持たせます。このベクトルは、その測定点の履歴情報を保持します。
情報の伝播メカニズム
システムは、2段階の学習プロセスを経ます。
特筆すべきは、このシステムが「ソフトリードアウト」と呼ばれる確率的な測定情報を活用できる点です。従来のデコーダーが測定結果を0/1の二値でしか扱えなかったのに対し、AlphaQubitは測定の確からしさも考慮に入れることができます。
AI技術が量子コンピューターの実現を加速し、その量子コンピューターがさらに強力なAIを生み出す—そんな技術革新の連鎖が始まろうとしています。
まず、AlphaQubitに代表されるAI技術は、量子コンピューターの最大の課題であるエラー訂正の問題を、解決に導こうとしています。これは、量子コンピューターの実用化への道を大きく加速します。実用化のタイムラインが、劇的に短縮される可能性があります。
そして、実用的な量子コンピューターが実現したとき、今度は量子コンピューターがAIの発展を加速します。量子コンピューターの並外れた計算能力は、現在のAIが直面している計算上の制約を打ち破り、より深い学習、より複雑なモデル、より高度な推論を可能にするでしょう。
これは単なる性能向上に留まりません。量子力学の原理を活用した「量子AI」には、従来のAIとは質的に異なる新しい可能性があります。量子重ね合わせや量子もつれといった現象を利用することで、現在のAIでは想像もできないような情報処理が可能になるかもしれません。
今回の論文で提示された世界観については、リープリーパーの過去記事も併せてお読みください。
AlphaQubitの開発成功は、AI技術と量子コンピューティングの融合がもたらす可能性の一端を示しました。量子誤り訂正という極めて技術的な課題に対し、Transformerに代表される最新のAI技術を適用することで、従来手法を大きく上回る性能を達成したのです。
しかし、実用的な量子コンピューターの実現に向けては、まだいくつかの課題が残されています。例えば、より大規模な量子システムでの性能実証や、リアルタイムでのエラー訂正の実現などです。
特に重要なのは、論理エラー率を1兆回の演算につき1回以下という、極めて低い水準にまで抑える必要があることです。AlphaQubitはその目標に向けた大きな一歩を示しましたが、目標達成にはさらなる技術革新が必要でしょう。
それでも、今回のブレイクスルーは楽観的な未来を示唆しています。AIによって量子コンピューターの実現が加速され、その量子コンピューターがさらに強力なAIを生み出す—このような技術の相乗効果は、私たちの想像をはるかに超えた可能性を秘めているのかもしれません。
リープリーパーでは、今年も量子コンピューターやAIに関するさまざまな話題を紹介していきます。どうぞお楽しみに!
[1]
[2]
[3]
[4]





