
時代が求める「説明可能なAI」-ブラックボックスを照らすXAIとは?
リプリパ編集部
リープリーパー


自然言語処理(NLP:Natural Language Processing)を含む深層学習は、本質的に強力な特徴学習とパターン認識の方法です。大量のデータから有用な特徴表現を自動的に抽出し、さまざまな複雑な知的タスクを完了させます。効率的な特徴抽出については、研究者たちが絶えず努力しながら研究を続けています。
今日の主役は、アテンション(注意力)です。アテンションとはこの用語どおり、AIモデルが人間のように、重要な情報に対して選択的に注意を向けることです。この機能により、人工知能モデルの質は飛躍的に向上を遂げました。現在よく知られているLLMモデル(ChatGPT、GoogleのBard、MetaのLLaMaなど)はすべて、このアテンションの恩恵を受けています。前回の記事では、自然言語処理の発展の歴史について紹介しました。今回は、自然言語処理の仕組みについて説明します。
まず、入力文を分割し、各単語を単語ベクトル列に変換します。簡単に言えば、自然言語を機械が理解できる数値の組に変換することです。このプロセスには通常、Word2Vec、BERTなどの、事前学習済み単語埋め込みモデルが使用されます。
以下の英文を例に説明します。
“She sings beautifully.”
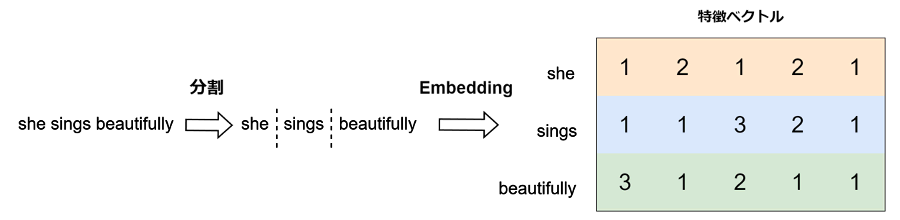
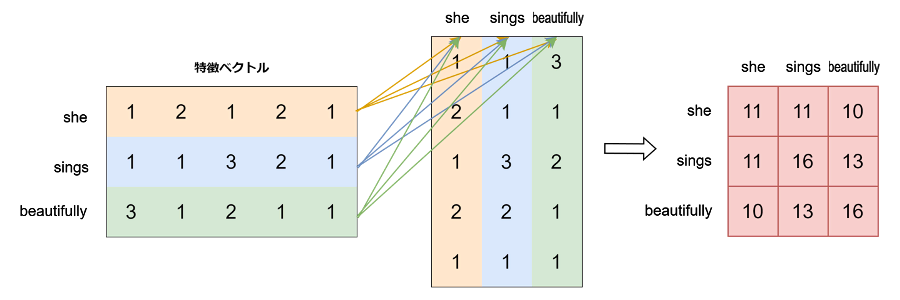
次に、各単語と他のすべての単語との関連性を計算します。ベクトルの内積が関連性を測る指標となります。
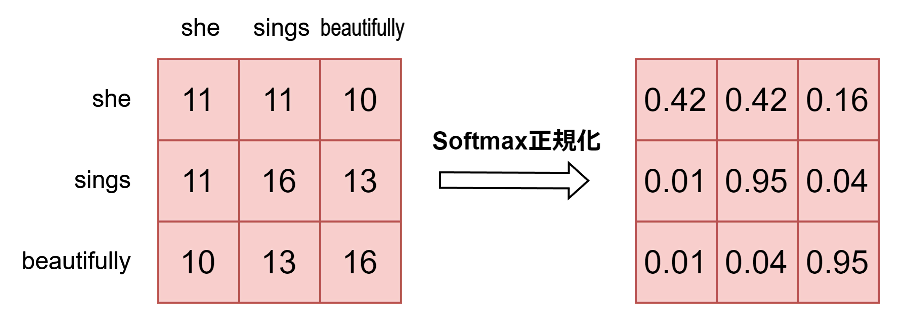
続いて、スコアにソフトマックス関数を適用し、アテンション重みを得ます。ソフトマックス関数は元のスコアを確率分布に変換し、すべての重みの合計が1になるように計算します。
次に、アテンション重みを使用してベクトルの重み付け和を計算し、コンテキストベクトルを得ます。このステップですべての関連情報が融合されます。

この例で一番右の結果に注目すると、次のことがわかります。
簡単に言えば、こういう傾向がわかります。
最後に、人為的にさまざまなパラメーターを調整し、機械が意味を正確に理解できるようにします。
もう一度 “She sings beautifully.” を見てみましょう。
“She”は文の主語として、他の2つの単語とある程度の関連性があります。”She”はまた、全体の動作の主体で、”beautifully”と間接的な描写関係があります。”sings”と”beautifully”の間には直接的な修飾関係があります。これは上記の計算結果と一致しています。
今回は、アテンション機構の仕組みを簡単に説明した例に過ぎません。実際にコンピューターに与える計算タスクはより複雑です。例えば、以下のような改善法が考えられています。
アテンション機構の革新的なアイデアは、2014年頃まで遡ることができます。注目すべきは、自然言語処理分野を本当に革新したのは、2017年に発表された”Attention is All You Need”論文で、Transformerアーキテクチャが導入されたことです。このアーキテクチャは完全にアテンション機構に基づいていて、従来の再帰型ニューラルネットワーク構造を排除しました。
▼[1706.03762] Attention Is All You Need
https://arxiv.org/abs/1706.03762
2017年から現在まで、わずか数年の間に、BERT、GPTシリーズ、T5などのTransformerベースのモデルが次々と登場し、自然言語処理技術の急速な発展を推進しました。ChatGPTなどの大規模言語モデルの成功は、まさにこれらの基礎研究の上に築かれたものです。
AIの発展は確かに爆発的な成長を示していますが、その背後には数十年にわたる基礎研究の蓄積と計算能力の指数関数的な向上があります。将来、AI技術がより多くの分野で重要な役割を果たすことが期待されています。例えば、医療診断や科学研究、教育の個別化などです。同時に、AIの発展がもたらす倫理的・社会的問題にも注意を払い、技術の発展と人類の福祉が調和するよう確保する必要があります。





