


ビジネスの意思決定を強力に支援する「数理最適化」とは何か?
理人
リープリーパー


どんなAIも、数学の言葉で言えばただの関数です。今回は、AI開発における「学習」とは何かを見てみましょう。現在の生成AIブームに代表される深層学習(ディープラーニング)の基本的な考え方は、簡単な数学の知識で理解できます。
AIの役割は、端的に言えば人間の知能作業を減らすことにあります。例えば、猫の絵を見て『これは猫だ』とか『猫ではない』と判定するような画像の分類作業は、AIが得意です。また、”Hello”という言葉を見て『これは日本語で”こんにちは”だ』という判定する翻訳作業も、AIが適しています。これらのタスクは、ひとつひとつが単純だとしてもその量が増えてくると、人にとって大きな負担になります。これらの知能作業をコンピューターにやってもらうのが、AIです。
画像の分類を例に考えます。コンピューター上ではデータは0と1で表現されます。なので、猫の画像も、結局は0, 1の数値の集まりに過ぎず、分類結果である猫だとか犬である、という出力も0, 1の数値の集まりに過ぎません。
そのため、例えば「画像分類器を作る」ということは、「数値と数値の間の関係を結ぶ」仕組みそのものだと言えます。数値と数値の間の関係を結ぶということは、私たちが中学生から使ってきた関数にほかなりません。AIの中身は関数なのです。

簡易的に関数を使って画像分類を表すと、
$f(x)=p$
です。$x$は入力データ(例:猫の画像)、$p$は出力データ(例:猫であるという判断)です。$f$が関数で「モデル」と呼んだりします。
また、実際に画像を分類する関数$f$が得られたとして、手元にある画像データに何が写っているかを画像分類器を使って判断することを、推論といいます。やっていることは単純に、データ$x$を$p=f(x)$に代入して$p$を計算しているだけです。
このように、どんなにすごいAIも、関数であると考えられます。現在主流の深層学習は、その関数の見つけ方に関する学問です。
関数を見つける、といっても実際に人が人力でやっているわけではありません。「関数探索(AIモデルの訓練と言ったりします)」は、人力でやるにはあまりに難しい問題です。正しく画像を判別できる良い関数があったり、そもそも画像判定すらできない悪い関数があったりと、無数にある関数の候補の中から最良の関数を見つけ出すのは非常に大変です。この関数探し自体に、コンピューターを利用しようというのが深層学習の枠組みであり、生成AIや自動運転をはじめとするAIの爆発的な普及を促しました。
以下では、関数を探すのにどのように深層学習が使われているか、3つのステップで解説します。
コンピューターを使って良い関数を探してもらうためには、「良さ」をコンピューターに理解できる形で定義する必要があります。関数の良し悪しを評価する数学的な枠組みは、期待外れ度(専門的には「損失関数」といいます)です。
例えば、画像を分類する場合、関数による分類がどの程度実際の分類と比べて間違っていたか、つまり期待外れ度を定義します。そして、その期待外れ度がなるべく小さくなるような関数$f$を探していきます。
数学的に表現すると、関数$f$に対してその期待外れ度$L(f)$を定義し、その$L(f)$が最小になるような、つまり最も良い関数$f$を探すことになります。
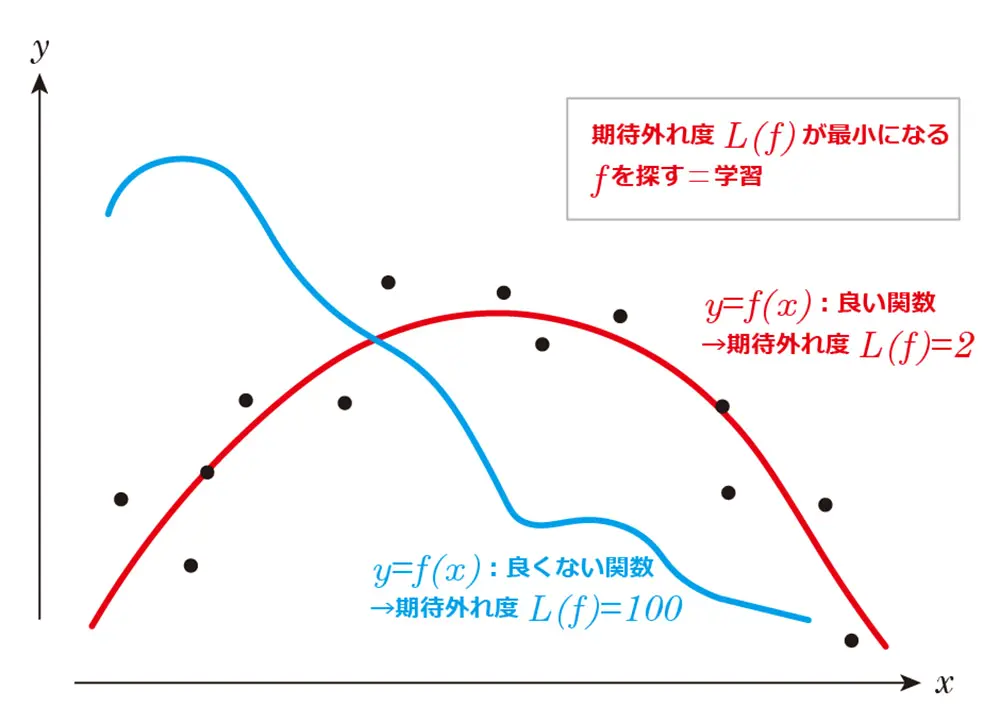
深層学習では、あらかじめ関数の形を具体的に指定して、その中から最良の関数を探すことを考えます。数学的にいうと、パラメーターを含む関数を用意します。
パラメーターのイメージは、中学校で習う直線の式
$y=ax+b$
における傾き$a$、切片$b$のように、その関数の具体的なふるまいを調整できる数値のことです。関数の用意の仕方、つまり関数の形及びパラメーターの種類や量を決めることが、深層学習における最も重要な作業である、分析モデルの設計に対応します。
実際には大規模言語モデルなどの生成AIに使われるパラメータの数は100万~1兆と非常に大きいため、直線の式よりもっともっと難しいモデルを計算することになります。
最後に、用意した関数の中で最良の関数を探します。先ほどの言葉を借りるなら、「最も期待外れ度が低くなる時のモデルのパラメーターを定める」ということです。
この作業をコンピューターが処理する時、たった一回の処理で最良の関数が見つかるということはなく、実際にはパラメーターの値をわずかに微調整させながら都度関数の期待外れ度を測っていき、その繰り返しによって最良の関数を探索します。
上記のステップの通り、深層学習による関数の探索は、実はとてもシンプルな手順に基づいています。ですが、実際にこれをコンピューターで処理する時の計算量は非常に大きく、関数探索には長い時間が掛かります。
そんなモデルの訓練のために、現在はGPUや線形代数理論の活用が必要不可欠になっています。リープリーパーでは、生成AIと量子コンピューター、線形代数とGPUとの関わりについての記事も書いていますので、ぜひ合わせてチェックしてみてください。
AIは、根底には簡単な数学的な仕組みがあります。このような基本的な理解が、より高度なAI技術やその応用について理解する第一歩となるでしょう。今後も、AIがどのように私たちの生活に影響を与えるのか、興味深く見守っていきたいと思います。
本質を捉えたデータ分析のための分析モデル入門 統計モデル、深層学習、強化学習等 用途・特徴から原理まで一気通貫! | 杉山聡 | 数学 | Kindleストア | Amazon





