



人間が結果を評価して精度UP!ChatGPTの学習メカニズムとは?
松原 太一
リープリーパー


筆者は、ゲノムインフォマティクスを研究する大学院生です。大規模言語モデルがゲノム解析にも使用されるようになってきた背景があり、DNA言語モデルを研究しています。リープリーパーでは、関連記事を複数書いています。
今回は、大規模言語モデルの最新の研究成果について、論文を読みながら、自分が理解したことと感想を述べてみます。今回扱うテーマは、状態空間モデルとMoE、そして最近報告が相次ぐハイブリッドモデルについてです。最近のモデルは、これまでの研究で得られてきた知見の総合芸術とでもいうべき、いろんな技術が複合されてできています。最新の技術トレンドを追っていきましょう。
一般に、大規模言語モデルの開発でよく用いられてきたのは、Transformerというモデルです。性能が高いのですが、欠点があります。それは、アルゴリズム的に計算機に要求されるメモリが高いため、長いコンテキスト情報の処理が遅くなるという点です。
最近になって、Transformerアーキテクチャを使わないMamba[1]、Hyena[2]といったモデルがでてきました。これらは状態空間モデルというカテゴリーに分類されます。
Mambaのような最近の状態空間モデル(SSM)は、RNN(Recurrent Neural Network 回帰型ニューラルネットワーク)よりも学習効率が高く、遠距離の関係を扱う能力も高いことで知られています。
状態空間モデルの基本的なアイデアは、負荷の高いTransformerの演算から脱却した、よりコンパクトな行列演算です。それでいて、Transformerのような、文脈に依存した選択的な情報抽出を可能にすることです。
状態空間モデルについてよく参考になる記事は、例えば以下です。英語の記事ですが、視覚的にめっちゃわかりやすかったのはこれです。
日本語だとこれが参考になります。
『複数の専門家を組み合わせて、合体させて、”最強の専門家MoE”を作りたいんですよ~』
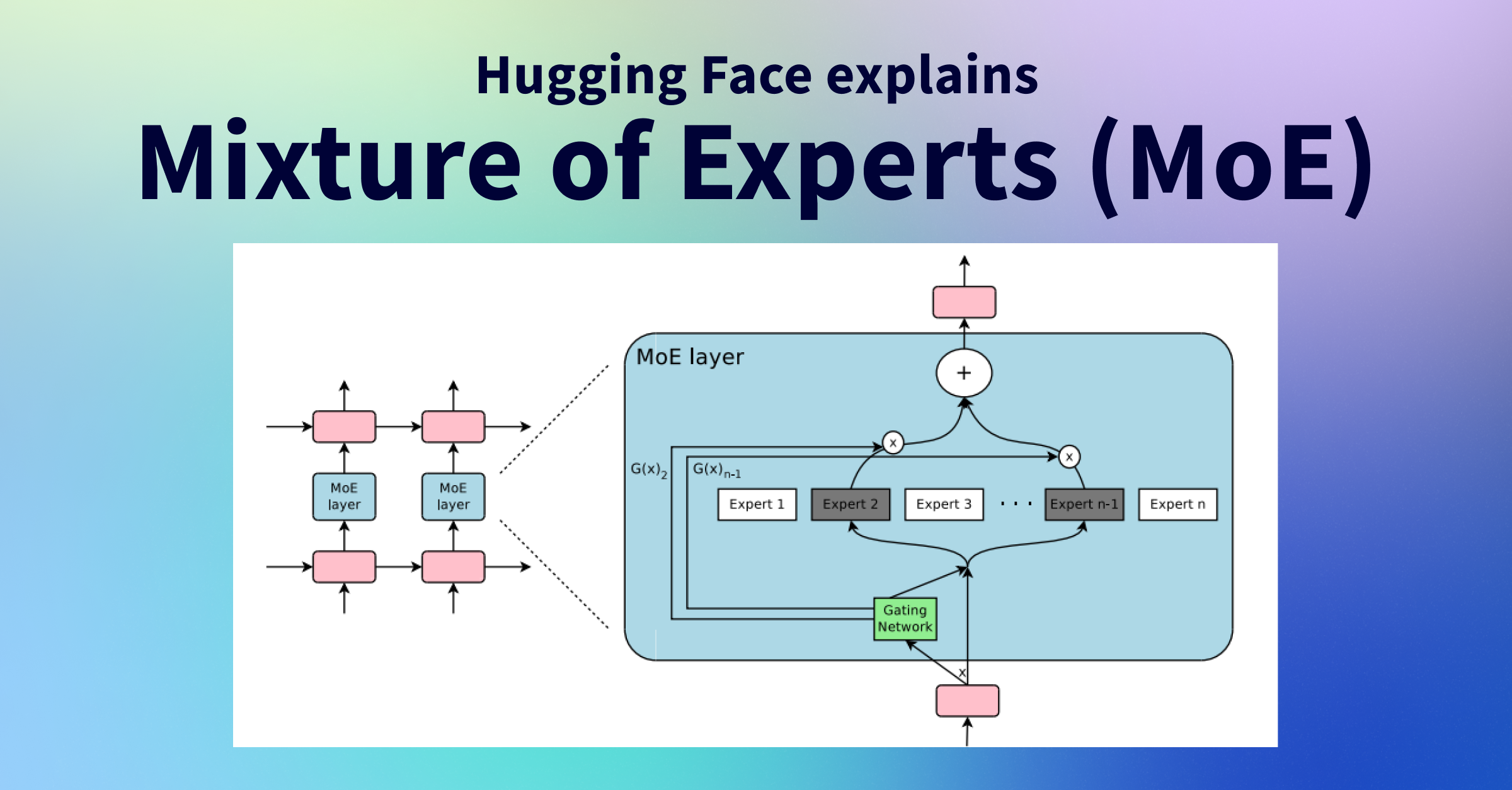
お笑いコンビのトム・ブラウンみたいな、このようなアイデアにあるのが、MoEと呼ばれる技術です。Mixture of Experts (MoE)は、複数の専門家(Expert)モデルを組み合わせてモデルの表現力を高める手法です。これは、計算コストも抑えられる手法のようです。
アイデア自体は、1990年代とかなり昔からある[3]らしいんですが、最近のLLMブームで再注目されているようです。MoEでは、通常の単一のモデルに情報のインプットを流すような機構とは異なり、複数のモデル群を作ります。そして、すべてのモデルが入力を処理するのではなく、選択的に処理することで、計算コストが抑えられます。エキスパート(専門家)と呼ばれる複数の異なる得意領域を有するサブネットワークを配置し、どのエキスパートが情報処理するかを動的に決定します。
MoEを使った最近の成果としては、Switch Transformers[4]が有名です。こちらは巨大な1.6兆パラメーターのモデルを実現し、同時に、通信コストや計算コスト、メモリ使用量を削減できたということです。MoEは計算要件(アクティブなパラメーターの数)を増やすことなく、モデル容量(利用可能なパラメーターの総数)を増やせるので、現在多くの開発者が注目している技術となっています。
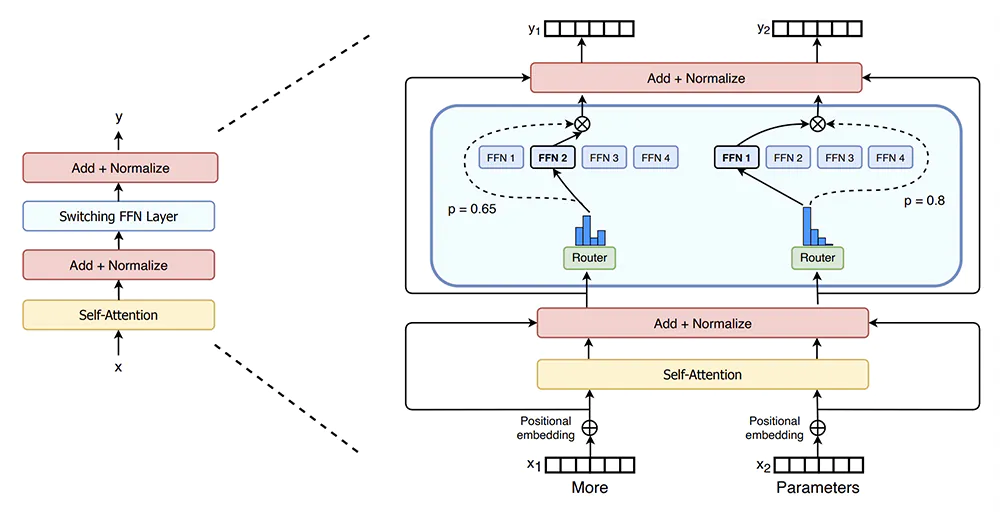
MoE解説だと英語の記事ですが、以下が分かりやすかったです。
日本語の関連記事はこちら。
つい先月2024年3月、異なる二つの研究グループから類似した研究報告が発表されました。その内容とは、すばり、「Transformerと状態空間モデルという異なるモデルクラスをひとつのモデルにハイブリッドで織り交ぜることで、非ハイブリッドな単一モデルよりも性能が上がる」というものです。
一方の報告は、AI21 Labsというイスラエルのテルアビブに拠点を置くスタートアップからです。彼らはJamba[5]と呼ばれるTransformer、Mamba、さらにMoEを組み込んだ大規模言語モデルと論文アーカイブを公開しました。2023年12月に発表されたMambaを組み込んだ、初の大規模なモデルクラスが公開されたことで話題となっています。

もう一方の報告は、Together AI、Stanfordなどの共同グループから出ています。最近の状態空間モデルであるHyena、MambaやTransformerモデル単体と、そのハイブリッドモデルに対して、性能評価基準(Mechanistic Architecture Design : MADと呼んでいます)を設けたベンチマークを実施[6]しています。その結果、言語モデルはハイブリッドで性能が上がったり、MoEで性能上がる等、全部で9つの発見を報告しています。
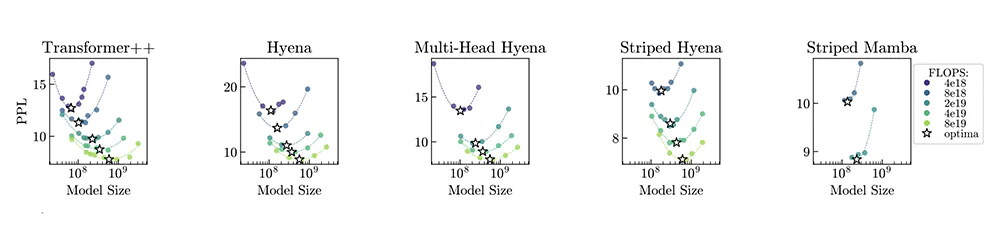
これらの主張は類似していて、今後、状態空間モデルがより活躍すると期待していいのではないでしょうか。MAD論文では、自然言語に限らず、さらにDNA配列コンテキストに対してもハイブリッドアーキテクチャ性能を評価しています。DNAも言語なので、やはり状態空間モデルの活躍が期待できそうです。
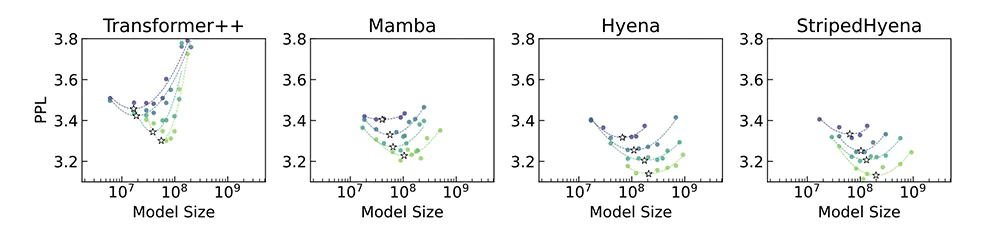
1年前と比べて、モデル設計に関してはだいぶ研究が進展しているようです。また、日が浅い状態空間モデルに関しては、研究が進んでくると、また新たな知見が増えてくるのではないでしょうか。
[1] Albert Gu and Tri Dao.Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752, 2023.
https://arxiv.org/abs/2312.00752
[2] Michael Poli, Stefano Massaroli, Eric Nguyen, Daniel Y Fu, Tri Dao, Stephen Baccus, Yoshua Bengio, Stefano Ermon, and Christopher Ré.Hyena hierarchy: Towards larger convolutional language models.In International Conference on Machine Learning, pages 28043–28078. PMLR, 2023.
https://arxiv.org/abs/2302.10866
[3] Adaptive Mixtures of Local Experts | MIT Press Journals & Magazine | IEEE Xplore
[4] Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity 2101.03961.pdf
https://arxiv.org/pdf/2101.03961.pdf
[5] Lieber, Opher, et al. “Jamba: A Hybrid Transformer-Mamba Language Model.” arXiv preprint arXiv:2403.19887 (2024).
https://arxiv.org/abs/2403.19887
[6] Poli, Michael, et al. “Mechanistic Design and Scaling of Hybrid Architectures.” arXiv preprint arXiv:2403.17844 (2024).
https://arxiv.org/abs/2403.17844





