ノーベル生理学・医学賞を受賞した炎症反応を抑えるmRNAとは?
松原 太一
リープリーパー


今回は、ChatGPTに搭載されているデータ分析機能Advanced Data Analysis(旧Code Interpreter)でできることや、具体的な使い方を紹介します。特に、データ分析をしている方や、興味があってこれからデータ分析に触れてみたいという方には、必見の内容です。
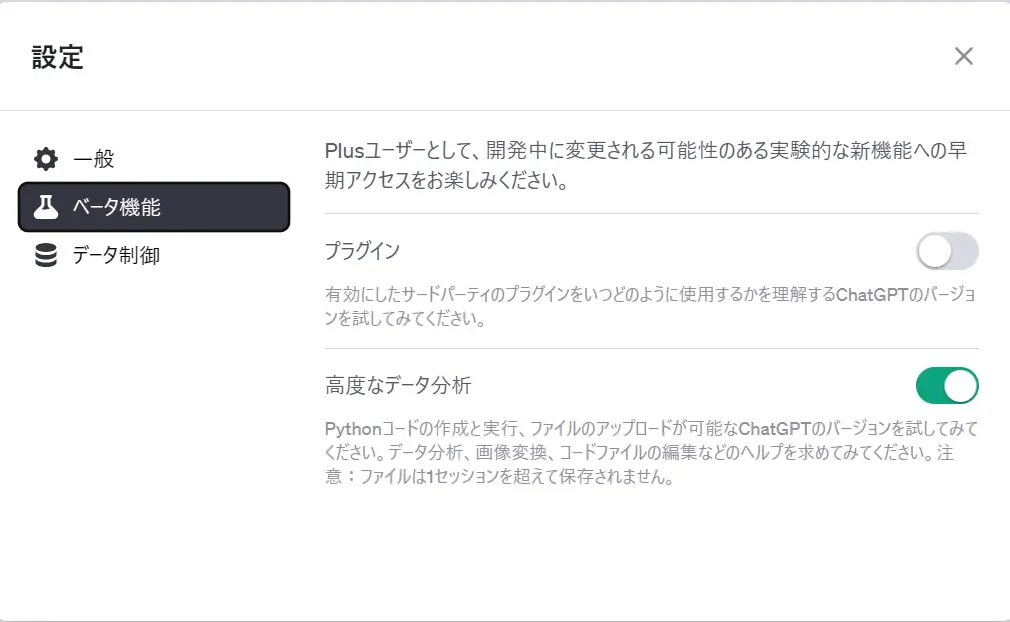
ChatGPTでAdvanced Data Analysisを使うには、月額課金プランであるChatGPT Plusを契約する必要があります(USD $20/月)。ChatGPT Plusを有効にし、モデルは「GPT4」を選択しましょう。設定のベータ機能で「高度なデータ分析」をオンにしてください。これで準備完了です。
Advanced Data Analysisで何ができるかは、本人(ChatGPT)に聞いてみましょう。以下が私とChatGPTとの問答の記録です。
Q(筆者):Code Interpreterを使うことで、何ができますか?
A(ChatGPT):Code Interpreterを使用すると、以下のような多くのタスクが可能です:
これらは一例であり、Code Interpreterの用途は非常に多岐にわたります。
なるほど、これは凄いですね!開発者や研究者がこれまで、スクラッチで行っていたようなプログラミング作業の多くを実行できるそうです。何ができるか分かったので、実際にAdvanced Data Analysisを使って、データ分析をする際に使えるデータの種類を確認してみましょう。これもChatGPTに聞いてみます。
Q(筆者):Code Interpreterを用いて処理できるテキストベースのファイルとコードファイルを教えてください。
A(ChatGPT):Code Interpreterを用いたデータ分析の基本的なワークフローは以下のようになります。
テキストベースのファイル:
コードファイル:
こちらも凄いですね。本当かどうか確認したところ、実際にどの形式も使用可能のようです。企業の業務でよく使用されるcsvやhtml、python等にも対応できるのが素晴らしいですね。早速、Advanced Data Analysis機能を使って、データの可視化とコードの解析をしてみます。
厚生労働省が公開しているオープンデータである、新型コロナウイルス感染症の日別推移のデータを使ってみましょう。下記URLをクリックし、図の黄色のところをクリックするとnewly_confirmed_cases_dailyという名前のcsvファイルをダウンロードできます。このファイルには、各都道府県の新規陽性者数の推移が記録されています。
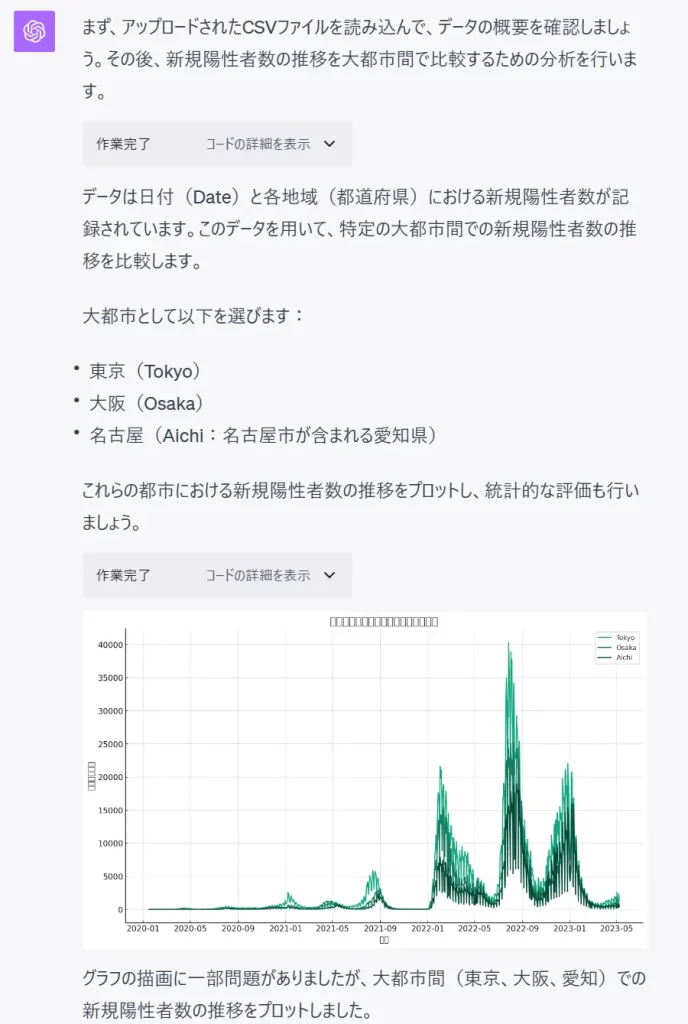
とりあえず、csvファイルをAdvanced Data Analysis上にアップロードし、何をしてほしいかをプロンプトで指示します。今回は、特に目的を設定せず、いくつかの大都市の推移のグラフを見たいという設定で、適当にプロンプトを作成しました。

プロンプトを与えると、下記のように与えたファイルの中身を見て自律的に解析作業を始めます。

さらに、統計結果を解析して考察まで
激やばですね。ざっくりとした命令に対して、どの都道府県を扱うか決め、グラフ絵画機能(matplotlib)を用いて爆速で描画し、基本的な統計情報と考察までしてくれました。
現状の図でグラフのタイトル部分がおかしくなっている理由は、グラフのタイトルに日本語フォントが適用できず、文字が表示されないからです。そこで、英語で表記するように指示したところ、最終的に以下の完成形の図を提示してくれました。
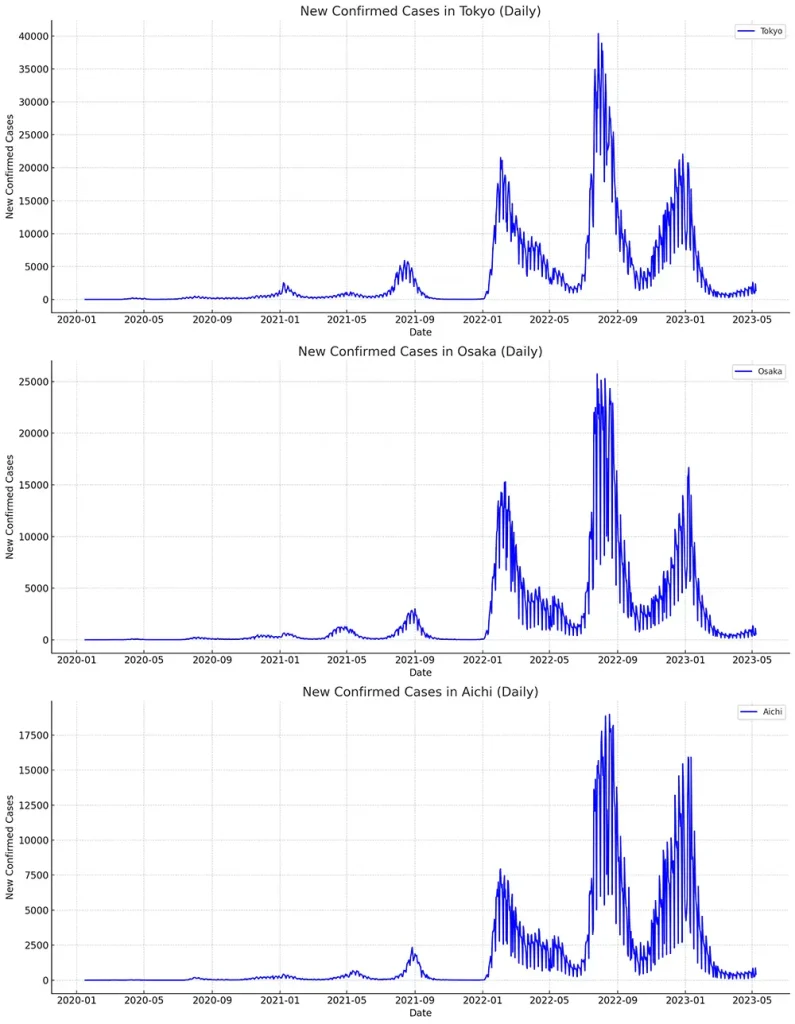
実際には個人の用途に応じて、より詳細にプロンプトを設計して目的に沿った解析結果を得られます。研究の用途においては、実験によって取得したデータの可視化・統計情報の解釈などに利用できます。
筆者は研究開発をしているため、下記のようなケースによくぶち当たります。エンジニアや他の業務においても、同様な事象は見られるかと思います。
こんな時に役立つのがAdvanced Data Analysisです。
深層学習モデルに関する新しい論文とそのGitHub実装が公開されたとして、そのアルゴリズムをざっくりと理解したいとします。論文はAlexNetの論文とし、その実装は下記のGitHubのものを解析したいとします。
▼Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. “Imagenet classification with deep convolutional neural networks.” *Advances in neural information processing systems* 25 (2012).
https://proceedings.neurips.cc/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html
▼GitHub – dansuh17/alexnet-pytorch: Pytorch Implementation of AlexNet
https://github.com/dansuh17/alexnet-pytorch
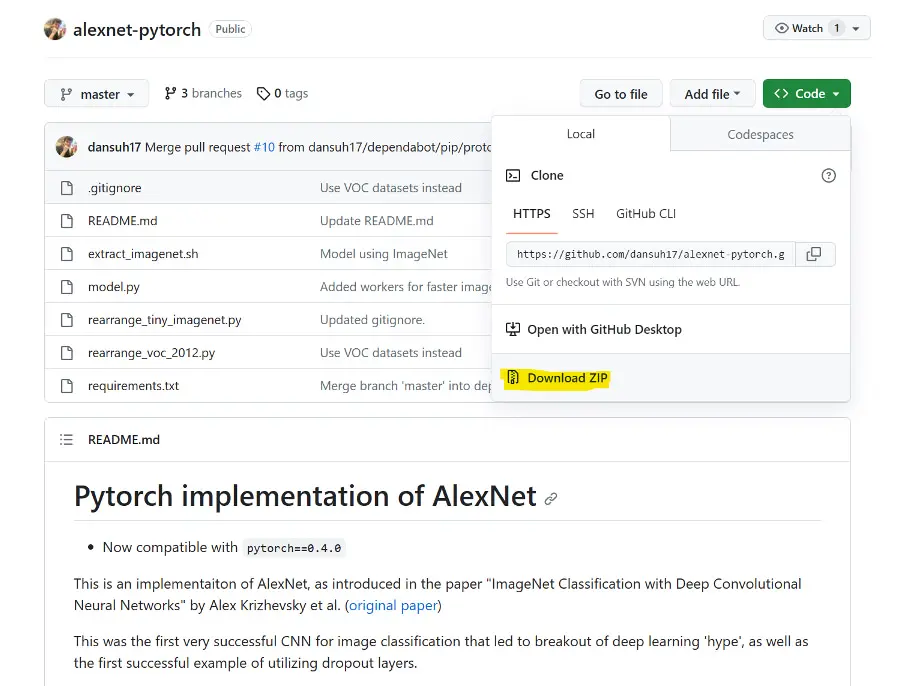
GitHubのページで緑のCodeボタンの矢印をクリックすると、黄色のようにZIPのダウンロードボタンがあるので、クリックするとダウンロードできます。
下記のようにプロンプトを作成し、ZIPファイルを添付してChatGPTに送信します。するとChatGPTがZIPファイルを解凍し、中身のディレクトリ構造を解析して、各種pythonファイル等を解析し始めます。

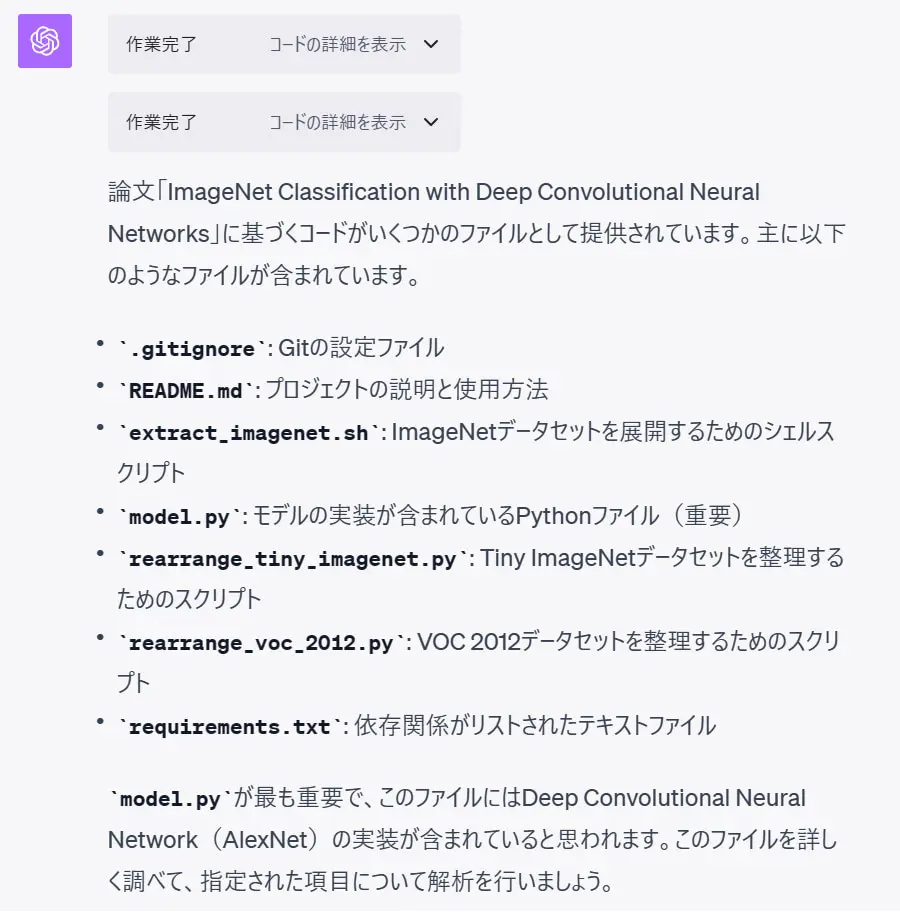
プロンプトを送信すると、ZIPの中身を解析し、以下のように質問に答えるための特に重要そうなファイル(model.py)にアタリをつけ、重点的に解析を始めたのが分かります。
解析が長引いてくると、レスポンスが止まったり、次の作業に移っていいかなどを確認してくることがあるので、その時は「続けてください」と返すと解析を続行します。

一連のやり取りを経て、結果的にChatGPTが下記の図のように出力してくれました。当初の命令通り、モデルの目的などを解説してくれています。ただし、一部出力に粗があるので参考程度に使いましょう。
これにより、『なるほど、このような意図のアルゴリズムなのか~』ということが、爆速で把握できます。時間のかかっていたコード解析が大幅に効率化します。

ChatGPTのAdvanced Data Analysisを使うことで、開発者に与えられる恩恵は多岐にわたります。例えば、効率的かつ効果的にコードを書くのを助け、問題解決、デバッグ、最適化のプロセスを高速化します。面白い使い方が他にあったら、ぜひコメントなどで教えてください。





