
生成AIでシンギュラリティーは前倒しされたか?―宗像仙人だより 10
リプリパ編集部
リープリーパー

近年、自動運転が話題になっています。サンフランシスコでは、Google系列のWaymo(ウェイモ)が自動運転タクシーを開始しました。日本では、エリアや地域が限定されているものの、高度な運転自動化である「レベル4」の試験的導入も始まっています。
人間が車を運転している時、人は道路標識や歩行者、他の車両などを識別し、瞬時に決定を下す必要があります。では、同じことをコンピューターに任せる場合、どのように実現するのでしょうか?研究者たちはAIを開発し、コンピューターの超高性能な計算力を利用してさまざまな問題を解決することに尽力しています。
今回の記事では、AIの目であるコンピュータービジョン技術を紹介します。
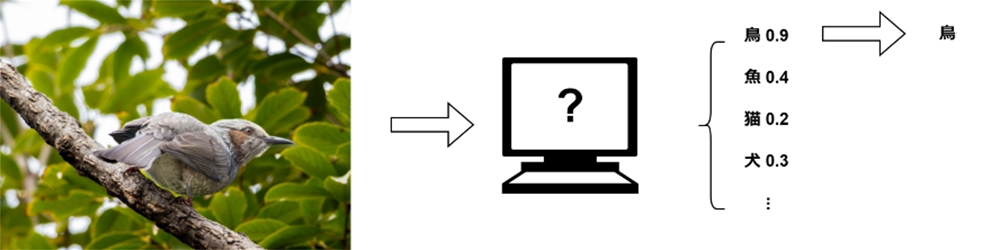
次の写真を見てください。

誰でも、これが車であることはすぐにわかるでしょう。つまり、人は写真を見て、被写体が所属するカテゴリーを分類したことになります。
次に、どのようにしてその結論に達したのかを、もう少し具体的に分析してみましょう。この被写体(物体)の形状やサイズ、色などさまざまな情報に基づいて下された判断です。
では、AIの場合、この一連の問題をどのように処理するのでしょうか?研究者は、コンピューターが人間のように視覚情報を理解し解釈することを「コンピュータービジョン(Computer Vision)」と呼んでいます。コンピュータービジョンは、画像やビデオの取得、処理、分析、理解を含み、有用な情報を抽出する技術です。
コンピュータービジョンにおける画像認識には、主に4つのタスクがあります:
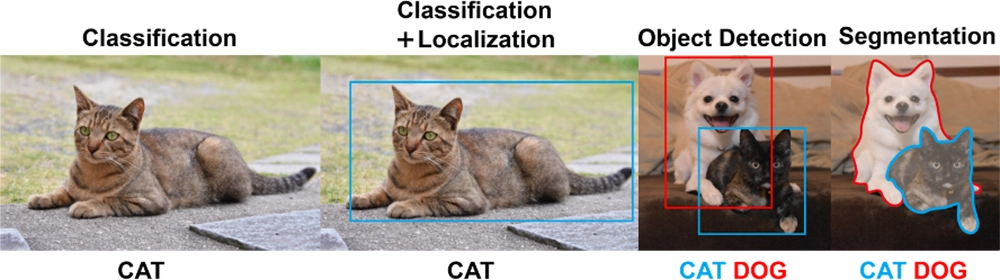
目標物の分類は、コンピュータービジョンにおける最も基本的なタスクです。人力で画像をチェックして分類するのは、非常に手間の掛かる作業です。数枚ならまだしも、膨大な画像の分類作業は、ほとんど不可能・非効率です。このプロセスを自動化し、対応するカテゴリーに基づいて迅速に画像にラベルを付けることで、AIは強力なサービスとして役立ちます。
コンピューターは大量の画像を分析し、各カテゴリーに対して、共通の特徴(例えば鳥の場合、その輪郭や嘴の形、尾の形、羽毛色の分布など)を見つけ出します。コンピューターはこれらの特徴に統計学的な意味での「重み」を与え、画像分類の問題を確率分布の問題に変換します。入力された画像にさまざまな処理を加え、計算された確率が鳥に近ければ、コンピューターはその画像を鳥として認識できます。
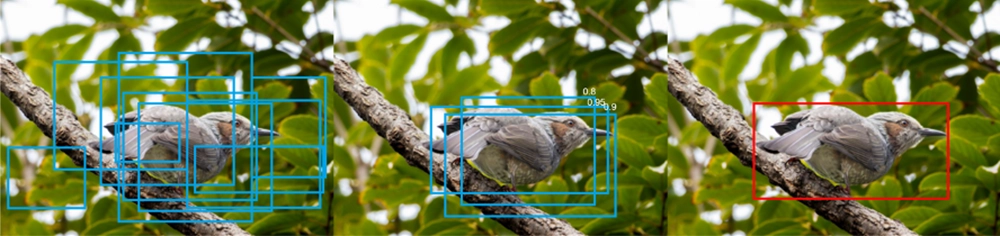
分類に基づいて、画像から対応する物体を見つけ出し、それらの物体の位置を正確に描画します(四角で物体を囲みます)。分類タスクを完了した後、コンピューターは物体の位置に候補領域を生成し、その後、候補領域内に大量の四角形(バウンディングボックス)を生成します。
次に、統計学的な回帰問題を処理します。簡単に言えば、バウンディングボックスの位置とサイズを正確に調整し、目標物体をよりよく囲むように調整します。
下の写真では、候補領域内に大量のバウンディングボックスを生成しています。中央の写真では、確率を算出し、確率の高いバウンディングボックスが残されます。右の写真では、最も確率の高いバウンディングボックスを結果として残します。
多くの皆さんがご存じかもしれませんが、画像は多くのピクセルの集合にすぎません。画像分割というステップは、特定のカテゴリーに属するピクセルを分類するプロセスです。つまり、画像分割はピクセル単位での分類タスクと見なすことができます。画像分割は、主に二つの大きなカテゴリーに分けられます。
前述の画像検出と異なって、画像分割は各ピクセルについて、その位置を考慮しつつ、他のピクセルとの関係性(主に物体の輪郭を区別すること)も分析します。その後、この関係性およびピクセル自体の特徴を確率分布問題に変換します。

この写真は、私が大学時代の研究で、このデータベースを使ってモデル訓練した結果です。 左側は、データベースからランダムに選択した、車載カメラが撮った写真です。右側は、それをセグメンテーション処理した研究成果です。車道や歩道、車、建物、歩行者、交通信号などがしっかりと区別されている様子がわかります。
研究者たちは、AIを開発するために多くの種類のデータセットを準備しました。その中でも最も古典的なものは、MNISTとCIFAR-10の二つです。
MNISTデータセットは、手書き数字画像のコレクションです。多くの研究者が学習テストとして使用し、手書き数字認識を研究するためのデータセットとなっています。
MNISTデータセットは4つの部分から構成されます。学習用画像(6万サンプル)、学習用画像に対応するラベル(6万ラベル)、テスト用画像(1万サンプル)、テスト用画像に対応するラベル(1万ラベル)です。手書き数字画像は、グレースケールです。

CIFAR-10データセットは、普遍的な物体を識別するためのデータセットです。コンピューター科学と認知心理学の研究者ジェフリー・ヒントン教授の下で学ぶ学生アレックス・クリジェフスキーが、博士課程の指導教官イリヤ・サツケヴァーと共に収集しました。飛行機や自動車、鳥、猫、鹿、犬、蛙、馬、船、トラックという、10種類のカテゴリーのRGB画像が用意されています。
CIFAR-10も、データセットは4つの部分から構成されます。学習用画像(5万サンプル)、学習用画像に対応するラベル(5万サンプル)、テスト用画像(1万サンプル)、テスト用画像に対応するラベル(1万ラベル)です。

コンピュータービジョンは自動運転の領域だけでなく、医療診断や顔認識、スマートホーム、ソーシャルメディアなど、すでにさまざまな領域で頻繁に使用されています。個人情報やフェイクニュースなどネガティブな面でも、防犯や健康管理などポジティブな面でも、私たちの日常生活に欠かせない存在です。
AIがコンピュータービジョンという目を鍛えているように、私たちも関心を持って技術の発展に注目し続けていきましょう。





