

GPT-4.5登場!人に寄り添った感情的な会話を研究者が試してみた
盛 堃
リープリーパー


2025年4月14日、GoogleのチーフサイエンティストであるJeff Dean氏が、チューリッヒ工科大学(ETH)で開催されたInformatics SymposiumでとAIについての講演を行いました。
タイトルを和訳すると、「AIの主要なトレンド:どのようにしてここにたどり着いたのか、今何ができるのか、そしてどのようにAIの未来を形作っているのか」。今回の記事では、Geminiシリーズの開発に至る経緯を簡単にご紹介します。
Kolloquium für Informatik | ETH Zürich Videoportal
https://video.ethz.ch/speakers/d-infk/2025/spring/251-0100-00L.html
Important Trends in AI: How Did We Get Here, What Can We Do Now and How Can We Shape AI’s Future?
https://drive.google.com/file/d/12RAfy-nYi1ypNMIqbYHjkPXF_jILJYJP
ニューラルネットワークの概念は20世紀に提案され、現在ではあらゆる種類のAI機能が、基本的にある種のニューラルネットワークベースのコンピューティングとして動作しています。ニューラルネットワークは、実際の人間のニューロン(神経細胞)の非常に不完全なレプリカだと、大まかに考えることができます。
2012年、Dean氏と他の研究者は、本物の大規模ニューラルネットワークは、訓練された小さなニューラルネットワークよりも優れたパフォーマンスを発揮すると主張しました。この取り組みの一環としてGoogleは、DistBeliefと呼ばれる、最初のニューラルネットワーク大規模インフラストラクチャ−システムを開発しました。 Dean氏は、「当時、データセンターにはGPUはなく、通常の古いCPUコンピューターがたくさんありました。このネットワークは、Imagenet 22K(画像認識の大規模データセット)でのAIの最高のパフォーマンスを、約70%改善しました」と説明しました
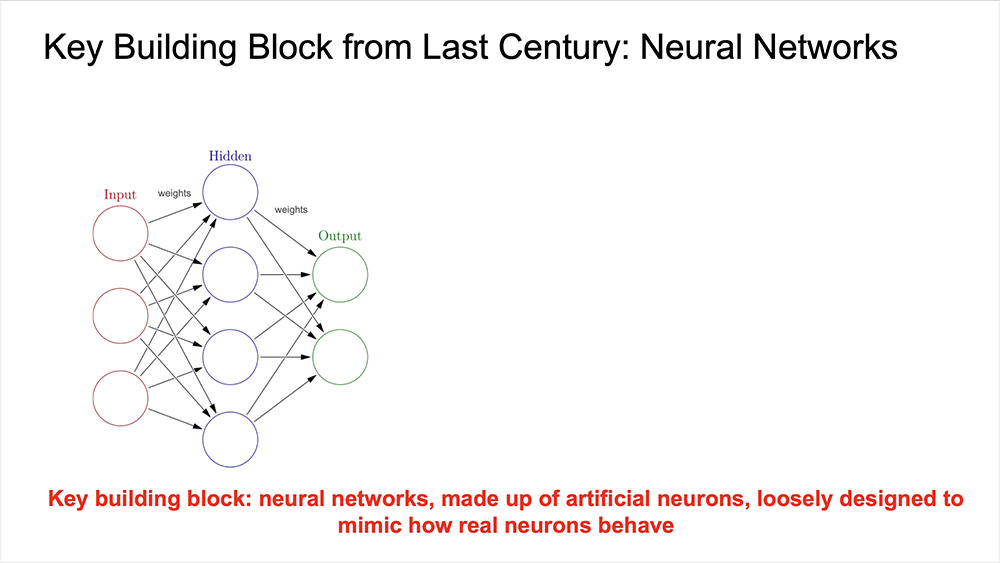
続いてDean氏は、「モデルのサイズが大きくなるため、音声認識などの便利なアプリケーションが登場し始め、ユーザー数が多くなる可能性があることを、2013年の時点で心配していた」と述べました。
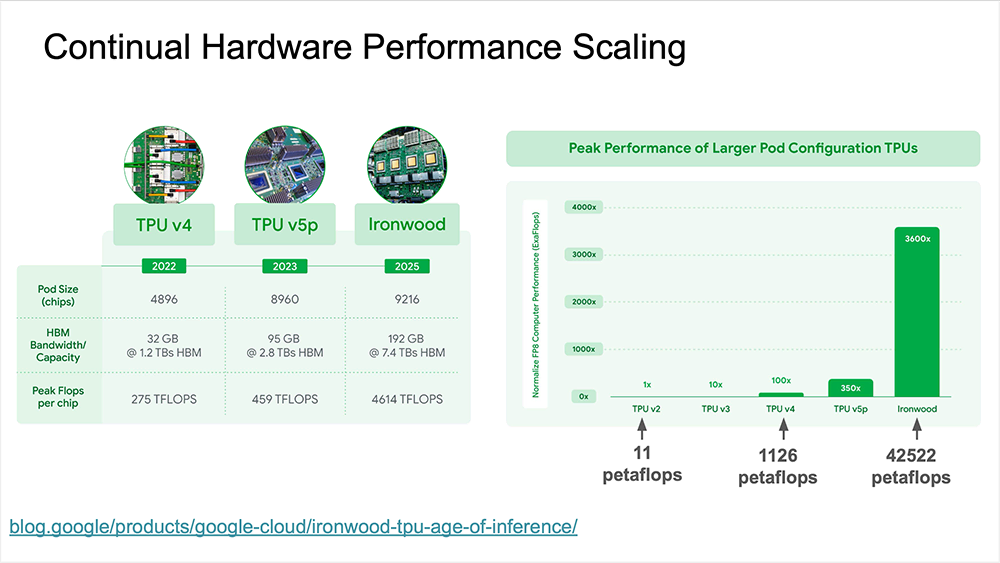
そこで、Googleはハードウェアの改善を試み始め、ニューラルネットワークの推論のために、よりカスタマイズされたハードウェアを構築することにしました。これは、TPU(テンサー・プロセッシング・ユニット)の起源です。最終的なTPUは、当時のCPUおよびGPUの15〜30倍高速で、これらのタスクでは30〜80倍のエネルギー効率でした。

その後Googleは、ニューラルネットワークのトレーニング専用のスーパーコンピューターの開発を開始しました。Google TPUポッドとして、元々は256ユニットのTPUが接続されていました。それが1,000、4,000、そして最近は8〜9,000と、非常に多くのTPUが接続され、推論とトレーニングの両方に能力を発揮しています。それらは、カスタマイズされた高速ネットワークで接続されています。
最近、GoogleはIronwoodと呼ばれる新世代のTPUを発表しました(Dean氏は、GoogleがこれからTPUを数字で命名しないとも述べました)。Ironwoodのポッドは9216チップと非常に大きく、各チップは4614 TFLOPS操作を実行できます。
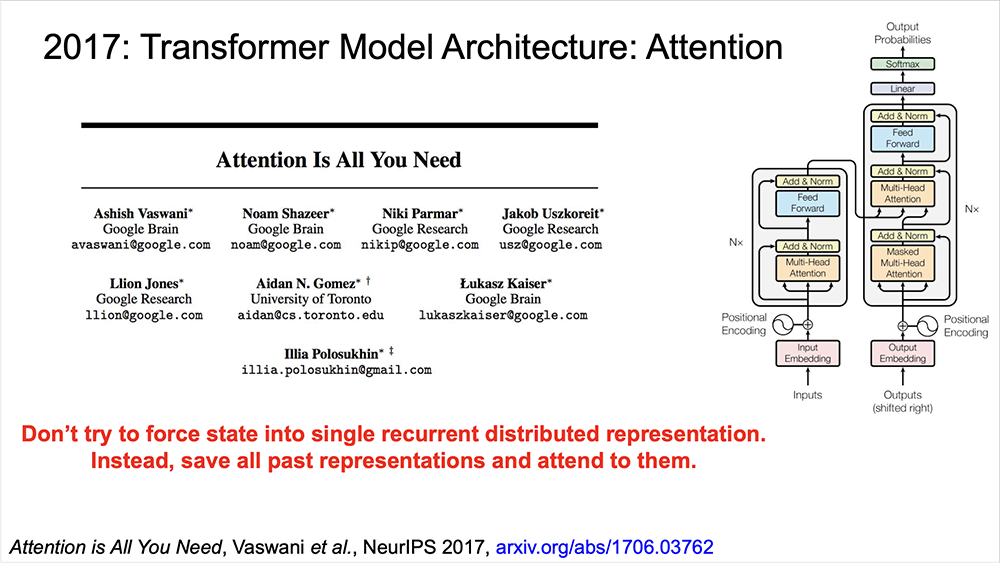
2017年、Transformerが生まれました。その時点で、ループモデルには順序立てた特徴的なプロセスがあることを観察しました。これは、一度に1つのトークンを吸収し、次のトークンを出力する前にモデルの内部状態を更新する手法です。この固有のシーケンシャルステップは、大量のデータから学習の並列性と効率を制限します。
彼らのアプローチは、すべての内部状態を保存し、アテンションと呼ばれるメカニズムを使用して発生したすべての状態をレビューし、現在実行中のタスクに最も関連している部分を確認することです(通常は次のトークンを予測します)。この理論の一部は、翻訳タスクで最初に実証されています。計算量が10〜100倍少なく、10倍の小さいモデルでも、当時の最も高度なLSTMまたは他のモデルアーキテクチャーよりも、優れたパフォーマンスを得られました。
次の図は、対数スケールを使用していることに注意してください。矢印(赤)で示す幅は小さく見えますが、実際には違いは非常に大きい効果を示しています。
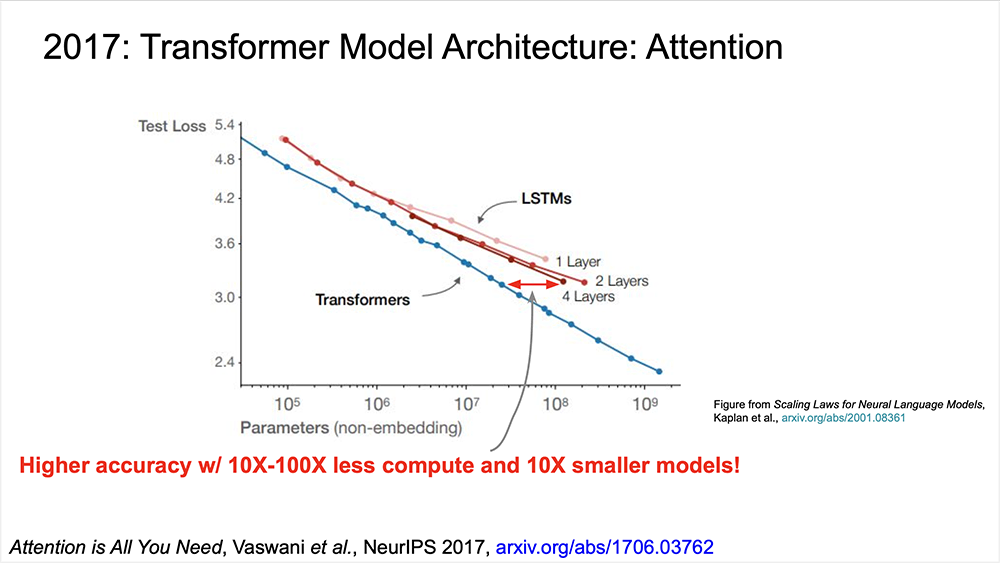
この論文は非常に重要で、現在ほとんどすべての最新の大規模言語モデル(LLM)は、Transformerまたはそのバリアントを基礎となるモデルアーキテクチャーとして使用しています。Transformerに関しては、リープリーパーの過去の記事でも説明したので、併せてご覧ください。
時間を少し飛ばして2023年になると、Googleはモデルの推論を高速化するSpeculative Decodingと呼ばれる技術を開発しました。大きなモデルよりも10〜20倍小さいモデルを使用する手法です。これは、小さなモデルで多くのことを予測でき、しかも遙かに高速に動作するアドバンテージがあります。
つまり、大小2つのアプローチを組み合わせて効率化させることが可能です。最初に、小さなモデルにk個のトークンを予測させ、次に大きなモデルに一度にk個のトークンを予測させます。このアプローチは、大規模なモデルで一度に1つのトークンを予測するよりも大幅に効率的です。

Dean氏は、「これらすべてが組み合わさって、今日、人々が目にするモデルの品質が大幅に向上します」と語っています。基礎となるTPUから高レベルのものへ、さまざまなソフトウェアと技術の進歩の開発により、最終的に強力なGeminiシリーズモデルが作成されました。
最後に、Dean氏はAIが私たちの社会に与えるプラスの影響のいくつかを共有しました。
「より多くの投資と人々がこの分野に入るにつれて、さらなる研究と革新が継続されると思います。モデルがますます強力になっていることがわかります。新たな人材は多くの分野で大きな影響を与え、より深い専門知識を得ることを容易にする可能性を秘めています。これは最もエキサイティングなことだと思いますが、一部の人々は不安を感じるでしょう。AIをアシストすることで、未来は明るいと思います」
Dean氏のスピーチには、他にも興味深い内容がたくさんあります。ここにすべてを挙げることはできませんが、興味のある方はぜひ冒頭のビデオを見たり、スライドを読んでみてください。
BlueMemeの研究チームでは、AIや量子コンピューター、バイオテクノロジーなど、次世代のITテクノロジーについて解説する記事を定期的に公開していきます。ぜひ、リープリーパーのソーシャルメディアアカウントをフォローして、次のアップデートを楽しみにお待ちください。





